https://www.yes24.com/Product/Goods/122109062
그림으로 배우는 리눅스 구조 - 예스24
선배가 옆에서 하나하나 알려주듯 친절히 설명해주는실습과 그림으로 배우는 리눅스 지식의 모든 것 * Go 언어와 Python, Bash 스크립트 실습 코드 제공* 이 도서는 『실습과 그림으로 배우는 리눅
www.yes24.com
오늘은 Computer Architecture의 유명한 아이디어인 메모리 계층 구조(Memory Hierarchy)에 대해 알아보겠다. 다음 그림을 보자.

위로 갈수록 CPU에 물리적으로 가깝고, 용량이 작고, 비싸고, 대신 속도가 빠르다. 이러한 원인은 결국 CPU에서 빠른 연산에 필요한 SRAM은 단위 메모리 당 면적이 크고 비싸지만 나머지 메모리인 DRAM같은 건 중간 정도의 면적, 빠르기, 비용이 들고, disk의 경우는 가격이 싼 대신 너무 느리다.
어쨌든 우리가 주목할 것은 '속도'이다. 그냥 CPU를 벗어나면 load/store 속도가 너~무 느리다고 생각하면 된다. 이를 위해 어떤 대안이 필요하다. 그것은 다양한 분야에서 적용되는 캐시(cache)이다.
1. 캐시 메모리
일반적으로 캐시 메모리는 CPU 내부에 존재하는 고속 기억장치로, CPU에서 캐시 메모리에 접근하는 속도는 일반 메모리에 접근하는 속도에 비해 수 배 ~ 수십 배 빠르다. 메모리에서 레지스터로 데이터를 읽어 들일 때, 일단 캐시 메모리에 '캐시라인'(cache line)이라고 부르는 단위로 데이터를 읽어서 그 데이터를 레지스터로 옮긴다. 이러한 과정은 하드웨어 적으로 이루어지므로, 커널은 간섭하지 않는다.
이 때 cpu에서 특정 데이터를 변경했다고 가정해보자. 그러면 변경된 데이터를 다시 메모리에 저장해야 하는데, 아까 말했듯, 메모리 저장 속도는 너무 느리다. 그래서 캐시에는 재미있는 기능이 존재한다. 바로 더티(dirty) 비트이다. cpu에서 데이터를 변경하거나, 또는 새로운 데이터를 메모리에 저장하고자 한다면, 캐시 메모리에 일단 저장하는데 이러한 캐시 라인을 dirty 하다고 이야기한다. 그리고 시간이 지나 이 캐시 라인의 데이터를 메모리에 쓴다면 dirty 표시는 사라지는데, 이때 메모리에 저장하는 방법은 Write-through와 Write-back 두 가지가 있다. Write-through는 데이터를 캐시 메모리에 씀과 동시에 메모리에도 기록하고, Write-back은 캐시에만 작성하고 나중에 시간이 되었을 때 메모리에 작성한다. Write-through는 구현이 간단하다는 장점이 있고, Write-back은 write 을 빠르게 처리할 수 있다는 장점이 있다.
만약 캐시되지 않은 데이터에 CPU가 접근한다면 메모리에서 캐시로 데이터를 올려야 한다. 이 때 캐시가 꽉 차 있고, 캐시 라인이 더티 상태라면 결국 캐시를 메모리에 저장하고, 필요한 데이터를 캐시로 올리고, 그걸 읽어야 한다. 생각만해도 긴~시간이 걸릴 것이다. 이렇게 캐시라인 내부 데이터를 빈번하게 교체하는 것을 스래싱(thrashing)이라고 하고, 스래싱이 자주 발생하면 처리 성능이 떨어진다.
2. 참조 지역성
CPU가 찾고자, 저장하고자 하는 모든 데이터가 캐시 메모리에 전부 존재한다면 정말 빠른 처리 속도가 나올 것이다. 이러한 현상을 참조 지역성(Locality of reference)라고 하고, 생각보다 자주 발생한다(캐시 연구에 인생을 바친 석박사교수님들 덕분이다..) 이는 다음과 같은 특징을 가진다.
- 시간적 지역성(Temporal locality): 어떤 시점에 접근하는 메모리는 가까운 미래에 또 다시 접근할 가능성이 높다.
- 공간적 지역성(Spatial locality): 어떤 시점에 메모리에 접근하면 가까운 미래에 그 "근처"의 메모리에 접근할 가능성이 높다.
따라서 프로세스가 메모리에 접근하는 모습을 보면, 보통 캐시 메모리 용량으로 커버할 수 있을 정도로 적은 메모리만 사용하는 것을 알 수 있다.
3. 계층형 캐시 메모리
최신 CPU는 캐시 메모리를 또 한번 계층화시켜서 관리한다. 그것을 각각 L1, L2, L3 cache라고 부른다. 1에 가까울수록 빠르며, 용량이 작다. 캐시 메모리에 대한 정보는 /sys/devices/system/cpu/cpu0/cache/index0/ 디렉터리의 파일 내용으로 확인할 수 있다. vim 에디터로 열어보니 다음과 같은 항목들이 있었다.

항목들마다 살펴보면 다음과 같다.
- coherency_line_size: 캐시 라인 크기(byte) 여기서는 64
- id: index{id} 여기서는 0
- level: L1 L2 L3중에 뭔지, 이건 L1이니깐 1
- type: L1d cache라서 data, index1 cache는 L1i cache라서 instruction, L2 L3 cache는 둘 다 하니깐 unified
- ways_of_associativity: 이건 몇-way associative인지 나와있다. L1d cache는 12-way이다.
- shared_cpu_list: cpu0~cpu7까지 있는데 몇번이랑 공유하는지? L1d cache는 0~1이라고 나왔다
- size: L1d cache는 48K, L1i cache는 32K, L2 cache는 1280K, L3 cache는 8192K 이다.
3. 캐시 메모리 접근 속도 측정
우리는 이론적으로 속도가 L1 > L2 > L3 임을 알고 있다. 따라서 각각 캐시 크기만큼의 버퍼를 순차적으로 확보한다면 접근 당 시간에 차이를 보일 것이다. 이를 테스트해보자.
* 주의! 각자 cache마다 용량 차이가 있기 때문에 필자처럼 캐시 크기를 측정하고 결과값과 비교해야한다.

L1d cache(48KiB)때 한번 꺾이고, L2cache(1280KiB) 언저리에서 한 번 꺾이는 것을 알 수 있다. 이로써 cache의 메모리 접근 성능 차이를 한 눈에 알 수 있었다.
4. Simultaneous Multi Threading(SMT)
앞에서 설명했듯 CPU의 계산 속도보다 메모리 접근 시간이 훨씬 길기 때문에, 보통 CPU 계산 자원은 놀고 있는 경우가 많다. 이러한 비어 있는 자원을 하드웨어의 SMT 기능으로 유용하게 활용할 수 있다. SMT는 코어 내부 레지스터 일부 자원을 여러 개 만들어서 각각을 스레드로 삼고, 커널은 이러한 스레드를 논리 CPU로 인식한다.
예를 들어 t0, t1 스레드를 가진 하나의 CPU에서 p0, p1 프로세스를 돌리려고 한다. 이러면 t0에 p0을 배정하고, t1에 p1을 배정할 것인데, 만약 p0 동작 중에 CPU의 자원이 비어 있다면, t0의 비어 있는 자원을 t1의 p1이 사용해서 처리를 진행할 수도 있다.
5. 페이지 캐시
데이터를 캐싱하는 캐시 메모리처럼, 페이지를 캐싱하는 페이지 캐시를 커널은 가지고 있다. 페이지 캐시는 파일 데이터를 캐싱하고, 물론 단위는 '페이지' 단위이다. 그 외에도 더티 상태를 표시하는 더티 페이지, 더티 페이지를 디스크에 다시 쓰는 라이트 백 개념도 존재한다.
즉, 지금까지는 디스크에서 프로세스(user) 메모리에 페이지를 복사한다고 가정했지만, 지금부터는 디스크 -> 커널 메모리(페이지 캐시) -> 프로세스 메모리(user) 로 향한다는 것이다. 이러한 과정을 만들기 위해서는 캐싱한 페이지에 대한 정보를 커널이 가지고 있어야 하고, 이러한 메타 데이터를 커널 메모리에 저장한다. 여기에서도 마찬가지로 dirty bit가 필요하다. 프로세스가 페이지에 대한 내용을 변경하면 이걸 커널의 페이지 캐시에도 변경하고, dirty bit를 켜 둔다. 여기에서 write back을 이용하면, 특정 타이밍에 디스크에 이 정보를 옮기고 dirty bit을 꺼준다.
만약 write-through 기법을 이용하고 싶다면 open()으로 파일을 열 때 0_SYNC 플래그를 설정해주면 된다.
6. 페이지 캐시 효과
1GiB testfile을 읽고 쓰는 시간을 측정해 캐시 효과를 체감해 보자. 우선 dd 명령어로 새 파일을 만드는데, 먼저 0_SYNC를 켜서 write-through로 만들어보자. 디스크에도 써야 하므로 시간이 꽤 걸릴것이다.

5.5s가 걸렸다. 이번에는 write-back 기법을 사용하자. oflag를 빼주면 된다.

이번에는 4.2초가 걸려서 시간이 단축됨을 알 수 있다. 아마 SSD가 빨라서 별 차이 없었지만 HDD에서 실습하면 큰 차이가 날 것이다.
이번에는 읽기를 할 것인데, 우선 testfile 캐시를 파기하기 위해 /proc/sys/vm/drop_caches에 3을 써보자.(이러면 testfile 뿐만 아니라 전체 페이지 캐시가 파괴된다.)
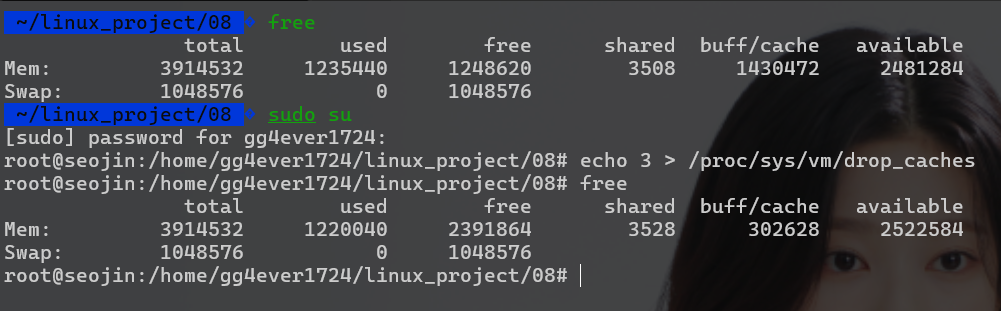
상당한 양의 캐시가 줄었음을 확인할 수 있다. 이렇게 testfile을 파괴하였으므로, 연속해서 두 번 testfile을 읽어보면서 cache의 "위력" 을 알아보자.

읽기도 수십% 빨라졌음을 확인했다. 끝날때 testfile을 삭제해주자( rm testfile)
7. 버퍼 캐시
페이지 캐시와 비슷한 버퍼 캐시는, 디스크의 데이터 중 파일 데이터 "이외의" 것을 캐시한다. 예를 들자면,
- 파일 시스템을 사용하지 않고 디바이스 파일로 저장 장치에 직접 접근할 때
- 파일 크기나 권한 등의 메타 데이터에 접근할 때
마찬가지로 dirty bit역시 존재한다.
8. 쓰기 타이밍
더티 페이지는 보통 백그라운드로 동작하는, 커널의 Write back 처리에 따라 디스크에 저장되는데, 동작 타이밍은 다음 두 종류이다.
- 주기적으로 동작, 기본값은 5초마다 1회
- 더티 페이지가 늘어났을 때 동작
Write back 주기는 sysctl의 vm.dirty_writeback_centisecs 파라미터로 변경할 수 있다. centisec은 센티초(1/100초) 이다. centimeter같은 느낌의 시간 단위라고 보면 된다.(왜 굳이 ms로 안했을까..)

500 센티초 = 5초임을 알 수 있다. 한편 시스템에 설치된 전체 물리 메모리 중에서 dirty page가 차지하는 비율이 특정 수치를 넘어가면 라이트 백 처리가 동작한다.

한편 vm.dirty_ratio는 전체 페이지 중 더티 페이지가 이 비율을 넘으면 더티 페이지가 심각하게 많은 상황으로, 커널은 모든 쓰기 작업을 멈추고 더티 페이지를 처리하는 걸 우선시한다. 보통 20이다.

9. 직접 입출력
대부분의 경우라면 페이지 캐시, 버퍼 캐시를 쓰는 것이 유리하지만, 다음과 같은 상황에서는 캐시가 없는(!) 편이 유리하다.
- 한 번 읽고 쓰면 두 번 다시 사용하지 않는 데이터의 경우: 예를 들어 파일 시스템의 데이터를 USB에 백업할 경우, 다시 그 파일 시스템에서 데이터를 쓸 일이 없으므로 굳이 페이지 캐시에 할당해서 읽을 필요는 없다.
- 프로세스가 자체적으로 페이지 캐시와 같은 기능을 구현한 경우 - 역시 페이지 캐시가 필요없다! (페이지 캐시는 SRAM이 아닌 메인 '메모리'상에 올라가므로 속도차이없음)
이럴 때는 직접 입출력(direct I/O)를 사용해 페이지 캐시 없이 처리할 수 있다. 이렇게 하려면 파일을 대상으로 open()할 때 O_DIRECT 플래그를 지정하거나, iflag나 oflag에 direct를 지정하면 된다. 다음은 dd 명령어로 직접 입출력을 하는 예시이다.

cache가 사실상 변하지 않았음을 알 수 있다.
10. 스왑
4장에서 free 영역이 거의 없어지면 OOM 상태가 되어 프로세스 메모리가 날라간다고 배웠는데, 스왑(swap) 기능을 사용하면 메모리가 고갈되어도 OOM 사태를 방지할 수 있다. 스왑은 저장 장치 일부를 일시적으로 '메모리'처럼 사용할 수 있는 기능이다. 시스템의 물리 메모리가 고갈된 상태일 때 더 많은 메모리를 확보해야 한다면, 사용 중인 물리 메모리 일부를 저장 장치로 옮기고 메모리에 빈 공간을 만든다. 이 영역이 스왑 영역이다.
시나리오로 표시하면 다음과 같다.
- A 프로세스가 500~700 점유하고 있고, B 프로세스가 700~800 점유하고 있고, C 프로세스가 800~1000 점유하고 있다. 이 프로세스에 해당하는 페이지 캐시와 페이지 테이블이 커널 메모리에 저장되어 있다. 점점 메모리가 줄어들면서 페이지 캐시도 다 없애버리고 해제가능한 buff/cache다 제거하고 했는데도 메모리가 부족한 상황이다.
- 이 때 B 프로세스의 물리 영역 100~200에 "접근"한다고 하자. 커널은 A 프로세스를 페이지 아웃(스왑 아웃) 시키기로 결정하였다. A 프로세스 600~700을 디스크로 스왑 아웃시키고 디스크의 주소를 페이지 테이블에 적는다. 그리고 B 물리 영역 100~200에 해당하는걸 600~700으로 옮긴다.
- 이후 C프로세스가 종료되어 메모리를 반납했으므로, 스왑 아웃된 A를 800~900으로 옮기고 페이지 테이블을 업데이트한다. 이 작업을 페이지 인(Page in) 이라고 한다.
페이지 폴트 중에서 페이지 인 때문에 저장 장치에 접근하는 것을 메이저 폴트(major fault), 그 외의 경우를 마이너 폴트(minor fault)라고 부른다.
스왑은 만능처럼 보이지만 사실 큰 문제가 존재한다. 바로 결국 디스크에 접근하기 때문에 너무 느리다는 것이다. 이렇게 페이지 인, 페이지 아웃이 반복되는 상황을 스래싱(페이지 캐시의 스래싱과는 다름!) 상태라고 한다. 이렇게 스래싱 상태가 되면 그때 OOM killer가 작동한다.
11. 통계 정보
이 페이지에서는 페이지 캐시, 버퍼 캐시, 스왑과 관련된 통계 정보를 sar -r 을 통해 알아볼 것이다. 처음에 뒤에서 배울 것이라고 말했던 지표들의 정체를 알게 될 것이다.

각각 필드를 정리하면 다음과 같다.
| 필드명 | 의미 |
| kbmemfree | 비어 있는 메모리 용량(KiB), 페이지 캐시, 버퍼 캐시, 스왑영역은 포함 안됨. |
| kbavail | kbmemfree + kbbuffers + kbcached |
| kbbuffers | 버퍼 캐시 용량 |
| kbcached | 페이지 캐시 용량 |
| kbdirty | 더티한 상태의 페이지 캐시와 버퍼 캐시 용량 |
kbdirty값이 평소보다 크다면 조만간 write back 같은 일이 일어날 것이라고 짐작할 수 있다.
한편 sar -B 명령에서도 배운 내용을 볼 수 있다.

정리하면 다음과 같다.
| 필드 | 의미 |
| pgpgin/s | 초당 페이지 인 데이터량(페이지 캐시, 버퍼 캐시, 스왑 영역 포함) |
| pgpgout/s | 초당 페이지 아웃 데이터량(페이지 캐시, 버퍼 캐시, 스왑 영역 포함) |
| fault/s | 페이지 폴트 수(major fault + minor fault) |
| majflt/s | 메이저 폴트 수(페이지 인 횟수) |
시스템의 스왑 영역은 다음 swapon --show 명령으로 파악한다.

또한 free를 했을 때 표시되는 Swap: 부분도 지금 보면 다시 보일 것이다.

현재는 여유로운 상태이므로 swap 영역은 0이라고 할 수 있다.
한편 sar -W 명령으로 스왑이 발생하고 있는지 체크할 수 있다.

또한 sar -S 명령으로 스왑 영역 이용 상황을 알 수 있다.

이상으로 리눅스에서의 캐시, 페이지 캐시, 버퍼 캐시, 스왑 영역에 대해서 자세하게 알아보았고, 다음 포스트에서는 블록 계층(HDD,SDD), 즉 저장 장치들에 대해 자세히 알아볼 것이다.
'Linux > 그림으로 배우는 리눅스 구조' 카테고리의 다른 글
| [그림으로 배우는 리눅스 구조] 10. 가상화 기능 (0) | 2024.08.31 |
|---|---|
| [그림으로 배우는 리눅스 구조] 9. 블록 계층 (0) | 2024.08.31 |
| [그림으로 배우는 리눅스 구조] 7. 파일 시스템 (0) | 2024.08.30 |
| [그림으로 배우는 리눅스 구조] 6. 장치 접근(2) (0) | 2024.08.30 |
| [그림으로 배우는 리눅스 구조] 6. 장치 접근(1) (0) | 2024.08.30 |